
AI活用の前に整える土台:マスタ参照を固定して“意味の揺れ”を止める(脱Excelの第一歩)

作業者のやり方は変えずに、作業時間を15倍短縮した話(まずは“基準点”を一本化した)
想定読者:Excel運用が限界に近い現場/入力ブックが複数あり、同名項目の意味ズレで手戻りが増えている担当者
結論
- 目標は 「Excelの見た目・文言は変えず」 に、トータル作業時間を短縮すること。
- 改善前は 入力120分+出力180分(合計300分)。
- 入力の手戻り主因は ルール解釈違い(70%)。人ではなく仕組みの問題だった。
- 最大の一手は マスタ参照を1箇所に統一(参照方法を固定=揺れを止める)。
- 結果、想定外データが無い場合は 300分→20分(約15倍)。次は **集計・出力から脱Excel(Sheets+GAS)**へ。
1. 何を短くしたのか(“トータル作業時間”の範囲)
今回の「トータル作業時間」は、次の2区分です。
- 区分①:データ入力(入力開始 → 入力完了)
- 区分②:集計・出力(入力済データ → 取りまとめ → 集計 → 出力完了)
主戦場は 区分① → 区分② の順で、両方です。
2. 改善前→改善後(Before / After)
- 入力(区分①):120分 → 15分(約8倍)
- 出力(区分②):180分 → 5分(約36倍)
- 合計:300分 → 20分(約15倍)
注:この短縮は 「想定外データが無い」(=前提が守られている)場合の実績です。想定外が出た場合は、後述の復旧手順で対処します。
3. 入力が遅い“本当の理由”(主因は手戻り)
区分①(入力)が遅くなる要因は次でした。
- 主因:手戻り(確認・差し戻し・記入漏れ)
- 副因:入力項目が多い/重複入力
さらに手戻りの内訳を出すと決定的でした。
- 記入漏れ:5%
- 入力ミス:10%
- ルール解釈違い:70%
- 確認待ち・承認待ち:10%
- その他:5%
つまり「入力が遅い」のではなく、“意味が揺れる” のがボトルネックでした。
解釈違いが起きる原因(代表例)
- 入力ブック(Excel)が複数あり、同じフィールド名でも意味が違う
- 参照する マスタ的データが正確に定義されていない
- 分割納品など 例外処理が煩雑 で、判断が増える
4. 制約条件(ここが肝)
今回は「作業者の作業方法は変えない」を明確にしました。
- 入出力ツール=Excelのまま
- 様式/見栄え/文言も維持
一方で「裏側」は変えてOK。
- マスタ整備:OK
- 集計方法:OK
- チェック機構:OK
- ファイル統合の仕組み:OK
(※入力補助:入力規則・ドロップダウン等は、現時点では未実施)
5. 最大の一手:マスタ参照を1箇所に統一(参照方法を固定)
結論から言うと、効いたのはこれです。
マスタ参照を1箇所に統一した
ここで重要なのは「場所固定」よりも 参照方法の固定。
「誰がどのファイルを見ても、同じ意味を参照する」状態をつくります。
参照方法を固定する“3段ロック”
- **Excelテーブル名(構造化参照)**で「意味」を固定
- VBAで参照先(シート名/テーブル名)を定数化して「参照の揺れ」を止める
- **ファイル名固定(VBAで担保)**で「入口」を固定(フォルダ固定も視野)
6. 集計・出力(区分②)で毎回やっていたこと
改善前、区分②は概ねこの3段でした。
- 分散ソースデータファイルを 一つに統合
- 出力に適ったデータ処理(抽出 → 並び替え → 集計:VLOOKUP相当をVBA)
- 出力
遅さの要因は、
- 主因:集計手順が複雑で、毎回同じ操作を反復
- 副因:整形・名寄せ・揺れ吸収が手作業
でした。
7. “想定外データ”が出たときの扱い(現状の運用)
現状は 集計後(出力結果)で検知して修正しています。
想定外データの例
- 半角空白/全角半角文字の混入(「無いはず」が混ざる)
- 想定していない組み合わせが存在し、抽出でエラー
復旧手順(5ステップ)
- エラーレポート(または抽出エラー箇所)を確認
- 該当行を特定
- 修正(空白除去/表記統一/マスタ追加など)
- 再集計
- 出力確認
8. データ辞書(フィールド辞書/マッピング表)
入力ブックが複数ある現場では、ここが“勝敗”を決めます。
同名フィールドでも意味が違うため、先に「対応表(辞書)」で意味を固定します。
図:フィールド辞書の例(WS×複数 ⇔ OUT-DATA)
※この記事では、実際の運用に合わせた表を「辞書」として固定しました。
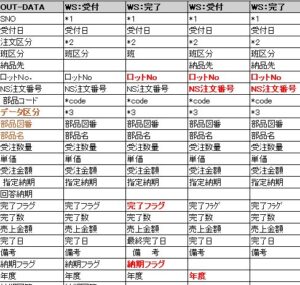
9. 脚注(*1 *2 *3 *code)の定義(辞書を“運用できる”形にする)
辞書の中でも、*印を付けた項目は「意味が揺れやすい/参照が必要/チェックが必要」な要注意ポイントです。
*1:識別子系(SNO / 受付 など)
- 定義:行を一意に扱うための識別子(連番/受付番号など)
- チェック:空欄NG/重複NG(重複時はエラー扱い)
- 備考(任意):統合時に重複しうる場合は「複合キー」を定義
*2:区分マスタ参照(注文区分 など)
- 定義:カテゴリを表す区分(解釈が揺れやすい)
- 参照:マスタ(唯一の参照先)を固定
- チェック:マスタに無い値はエラー(想定外データ)
*3:データ区分(処理分岐に直結)
- 定義:処理の分岐に使う区分(抽出条件に直結)
- チェック:未定義値は抽出エラーとして止める(黙って落とさない)
*code:部品コード(未付与・表記ゆれが起きやすい)
- 定義:部品を一意に表すコード(未付与が発生しうる)
- 正規化:前後空白除去/全角半角統一/表記ゆれ統一
- 補完:未付与時はマスタから補完、補完不可はエラー
10. キー設計(名寄せの中心)
統合・名寄せの主キーは次です。
- 伝票番号+品番 を Hash化してキー化
11. このやり方が効く現場条件
- 入力ブックが複数ある
- 同名項目でも意味がズレている
- 名寄せが発生する
- 集計が毎回ほぼ同じ手順(期間などパラメータが違うだけ)
12. 次の一手:脱Excel(集計・出力から)
次の改善ターゲットは 脱Excel。
当面は 集計・出力(区分②)から置き換えます。
- 置き換え先の第一候補:Google Sheets + Apps Script
まとめ
人を変える前に、基準点(マスタ参照)を一本化すると、手戻りの大半は“勝手に減る”。

